Event arc
Faster fine-tuning enables quicker deployment of customized AI models.
Cluster
Collecting the cluster map, linked briefings, and market context.
AI BriefWire / Thread
NVIDIA and Hugging Face introduced NeMo AutoModel to speed up fine-tuning of transformer models. This tool automates model selection and optimization, reducing time and complexity. It helps developers efficiently adapt large language models for specific tasks.
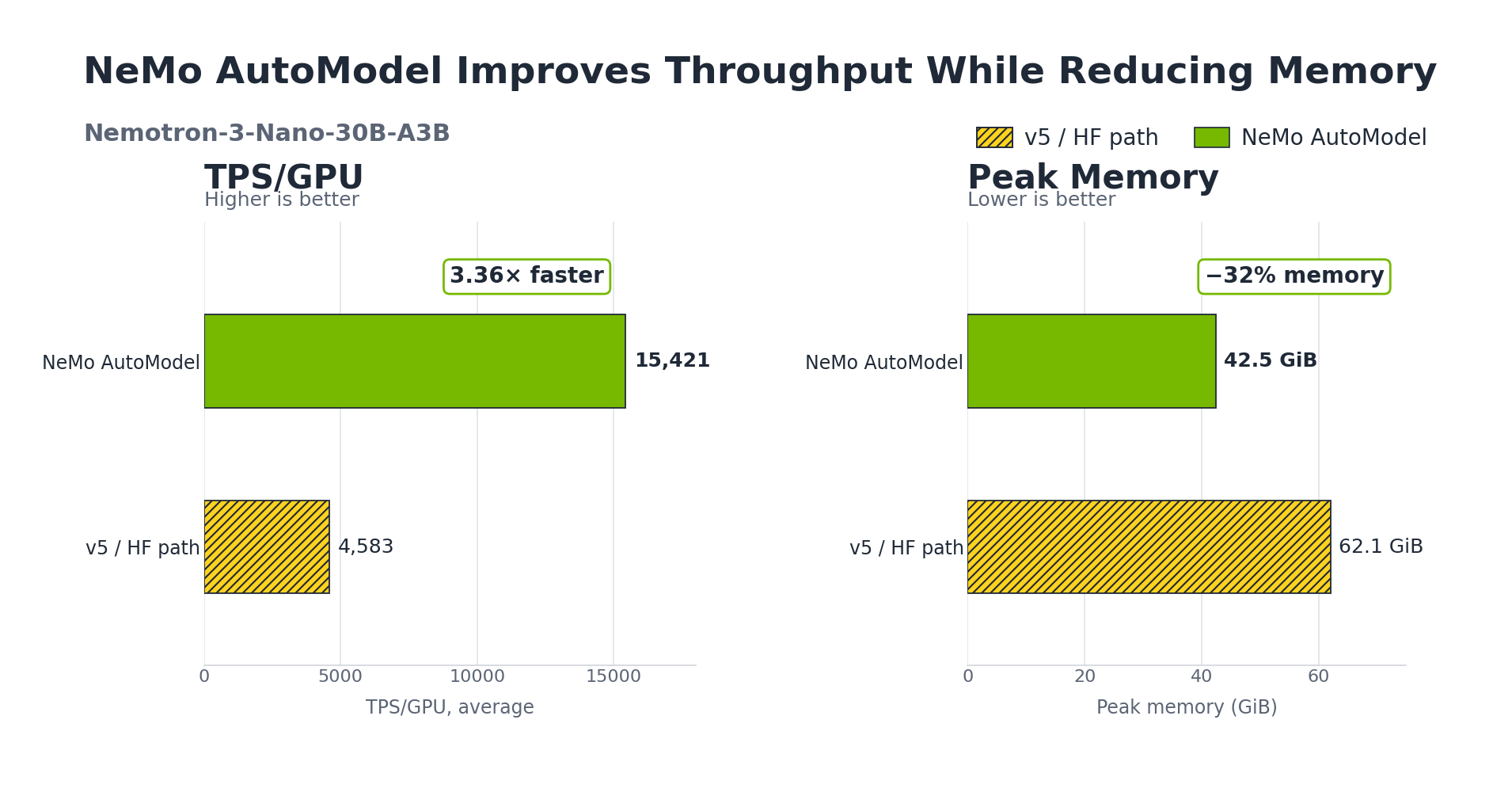
Faster fine-tuning enables quicker deployment of customized AI models.
NVIDIA (NVDA)
Reduces development costs and accelerates AI product time-to-market.
Teams working with transformers should consider integrating NeMo AutoModel to improve efficiency.
Sources in this thread (1): Hugging Face Blog
Read the development of the event across sources, timestamps, and editorial cues.
Latest signal
NVIDIA and Hugging Face introduced NeMo AutoModel to speed up fine-tuning of transformer models. This tool automates model selection and optimization, reducing time and complexity. It helps developers efficiently adapt large language models for specific tasks.
Open individual briefings or jump to the original reporting.
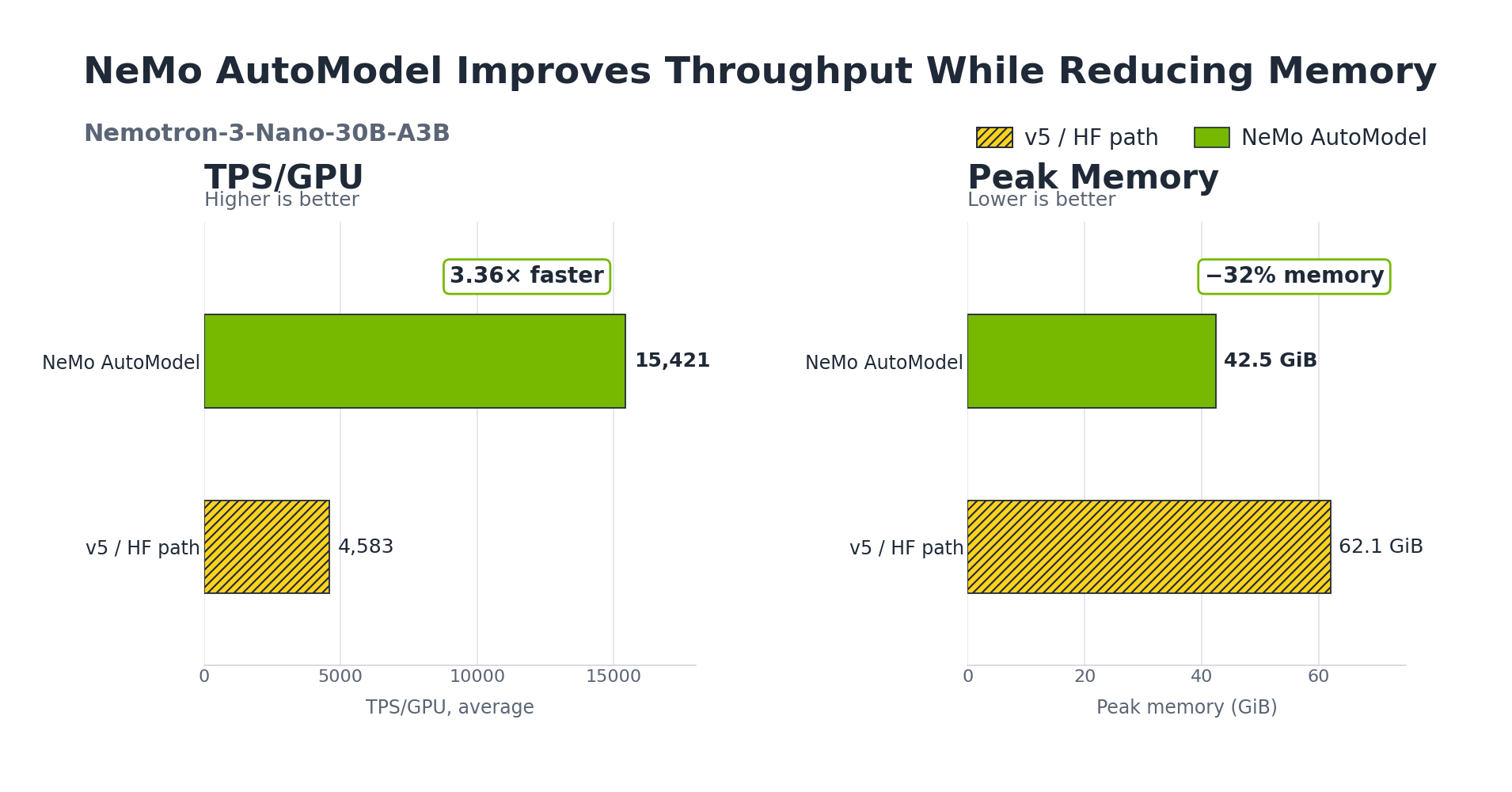
NVIDIA and Hugging Face introduced NeMo AutoModel to speed up fine-tuning of transformer models. This tool automates model selection and optimization, reducing time and complexity. It helps developers efficiently adapt large language models for specific tasks.