Original article excerpt
Server-side extracted preview paragraphs from the original source.
The
*Unity Catalog is now the most comprehensive, interoperable, and production-ready Apache Iceberg catalog, with Managed Iceberg, Iceberg v3, and Foreign Iceberg moving into GA. *Five capabilities set it apart: open APIs, catalog federation, cross-engine access control, zero-copy secure sharing, and AI-driven optimization. *Looking ahead, Iceberg v4 and Delta 5.0 will converge on a unified metadata structure, ending the tradeoff between interoperability and production-ready performance.
The next phase of the open lakehouse will be defined by the catalog. Open table formats made it possible for many engines to work on the same data, but the catalog determines whether that data can be governed, optimized, and shared consistently across systems. As more workloads, including AI and agentic applications, depend on governed access to data across many systems, enterprises need an Iceberg catalog that can provide interoperability, great performance, and enterprise-ready governance.
That is why today, we are announcing the most comprehensive set of Iceberg capabilities available on any lakehouse catalog. In this blog, we will discuss new enhancements for Iceberg support in Unity Catalog and break down 5 things that make Unity Catalog the most interoperable Iceberg catalog on the market today.
We’ve pushed a broad set of Iceberg capabilities across Databricks and Unity Catalog into General Availability and Preview to ensure every engine, every catalog, and every team can work seamlessly together.
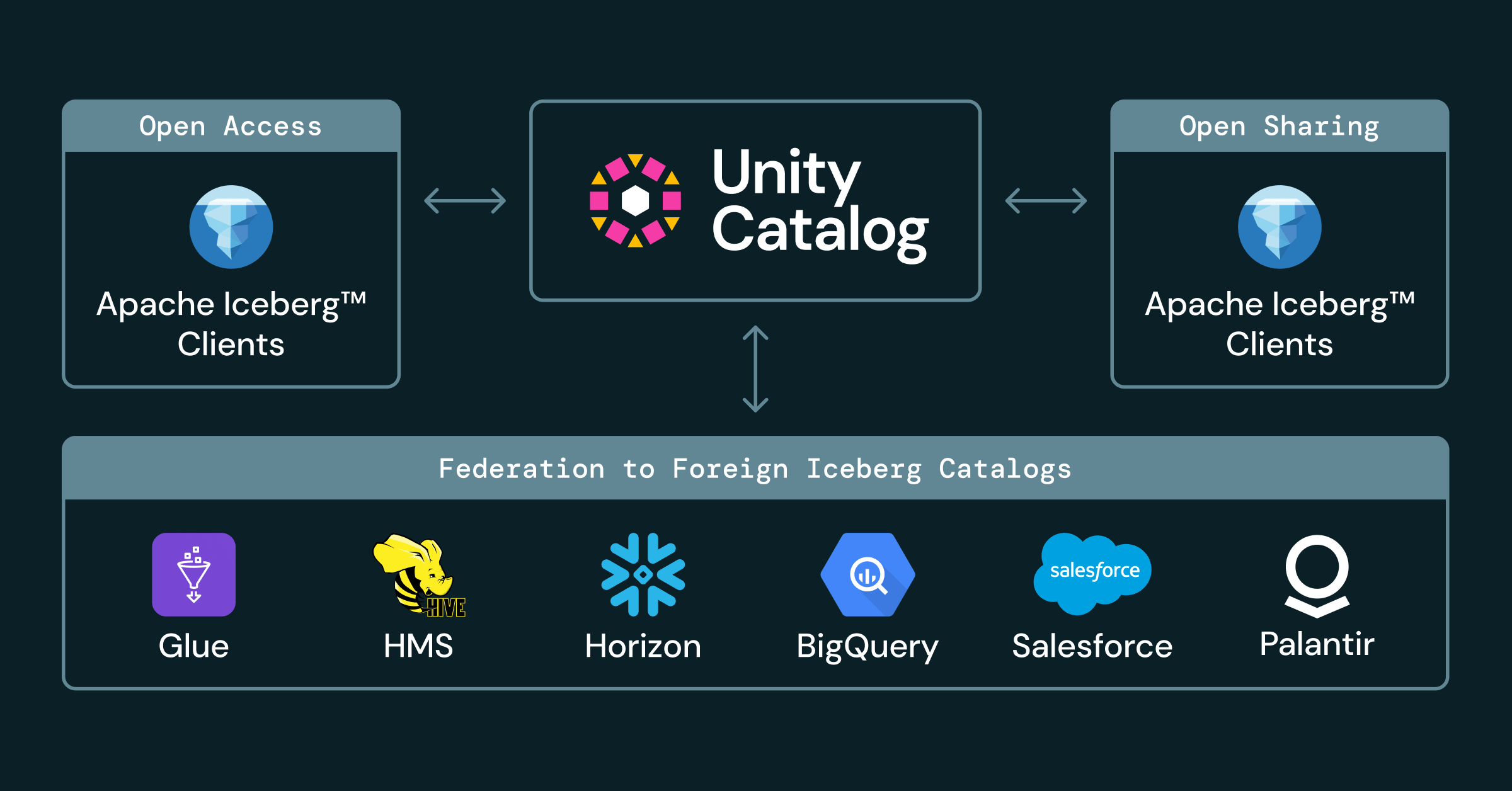
To deliver a fully open lakehouse, an Iceberg catalog must go beyond basic metadata tracking. It needs to give you absolute flexibility across diverse engines, vendors, and governance models. We believe evaluating an open Iceberg catalog comes down to how well it addresses five fundamental operational requirements: providing open APIs, federating across external estates, enforcing cross-engine governance, enabling secure and open sharing, and continuous performance and format innovation.
Customers should be able to use the engine that best fits the workload, whether Spark, Trino, Flink, Snowflake, DuckDB, pandas, or another Iceberg-compatible client, without copying data or giving every engine broad storage permissions.