Original article excerpt
Server-side extracted preview paragraphs from the original source.
When
When I started my PhD at UC Berkeley 16 years ago, my advisor told me: "OLTP databases are a solved problem. They work. Focus on analytics." We were at the early innings of being able to collect far more data, structured and unstructured, and apply machine learning (which we now call “AI”). So I took the advice and joined my cofounders on the research project that became Apache Spark, and later on we started Databricks.
As we built Databricks, we started using various databases out there, and we realized OLTP databases were far from a solved problem: they were clunky, difficult to scale, and incredibly fragile. We were frustrated enough at some point that we asked ourselves what an OLTP database would look like if we were to design it today. That question led to Lakebase, our serverless Postgres database.
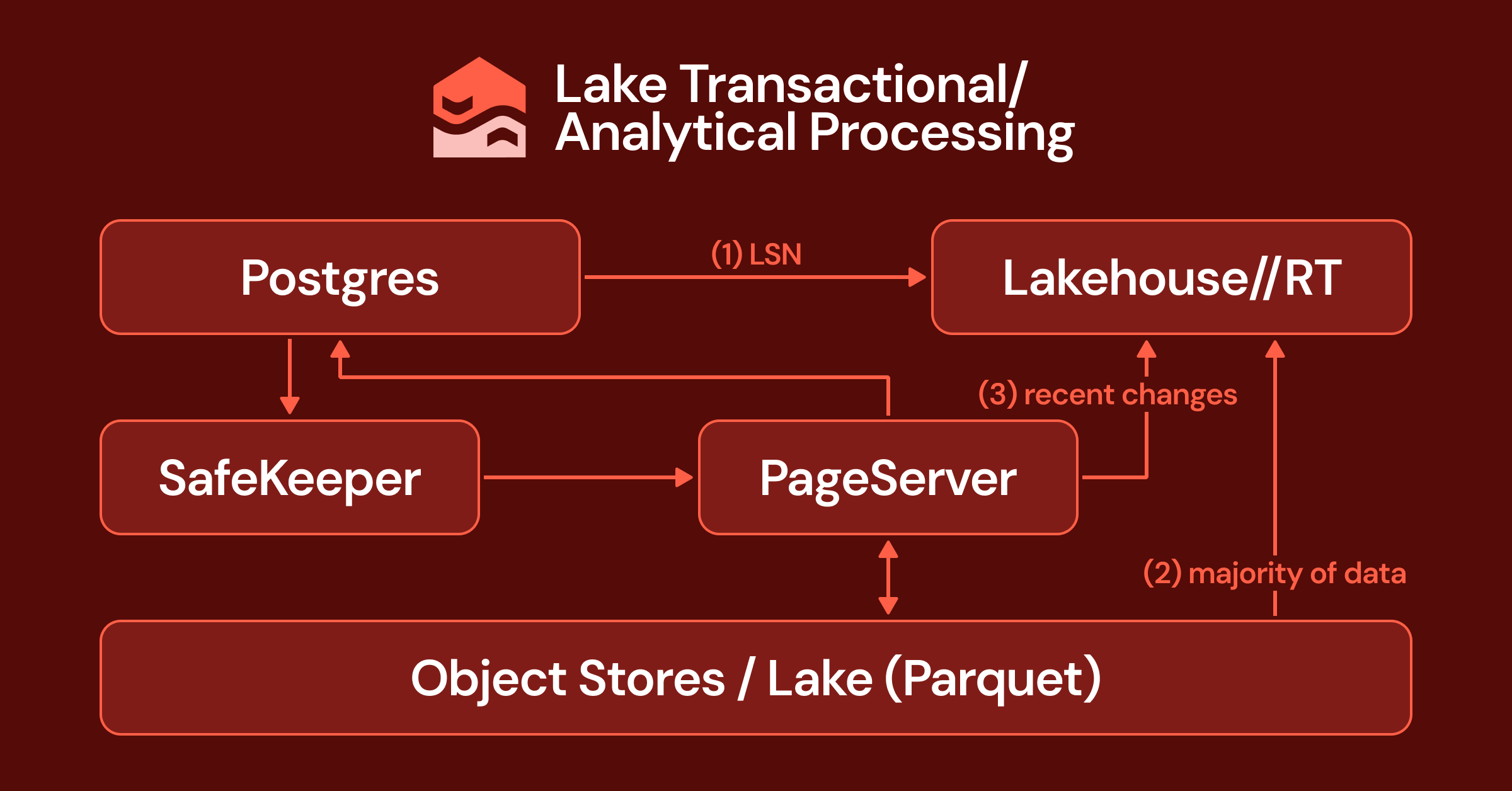
This post takes a deep dive into the Lakebase OLTP architecture. We start at the storage layer of a traditional monolithic database to see where the pain comes from, then we look at how Lakebase rearranges those same pieces into independent, externalized services. Finally, we turn to LTAP, where that same architecture lets transactions and analytics run on a single copy of the data, in real time, without the delays and extra cost of CDC or "mirroring.”
The vast majority of databases running in the world today are monoliths. This includes MySQL, Postgres, classic Oracle. Lakebase is built on Postgres (as it happens, was also born at Berkeley), so we will be using Postgres as the primary example here, but most databases work similarly: You provision one machine that runs the database engine and the storage. In these database systems, there are two things on disk that matter the most: the write ahead log (WAL) and the data files.
When you commit a transaction, the database does not immediately go and rewrite the data files. That would be slow, because the rows you are touching are scattered across the file in places that require random I/O. Instead, the database first appends a description of the change to the WAL, which is a sequential log on disk. A transaction is considered committed the moment that log entry is durably written. Only later, asynchronously, does the database go back and update the actual data files to reflect the change.
One simple way to think about this: the WAL exists to make writes fast (and safe), and the data files exist to make reads fast. The log lets you commit a transaction with a single sequential append instead of a scattering of random I/O. The data files let you answer a query by reading the current state directly, instead of replaying the entire history of the database from the beginning of time. (If you want to understand all the intricate details of this design, read the 69-page long ARIES paper. Be warned that this is one of the most complex papers in computer science.)