Original article excerpt
Server-side extracted preview paragraphs from the original source.
Heal
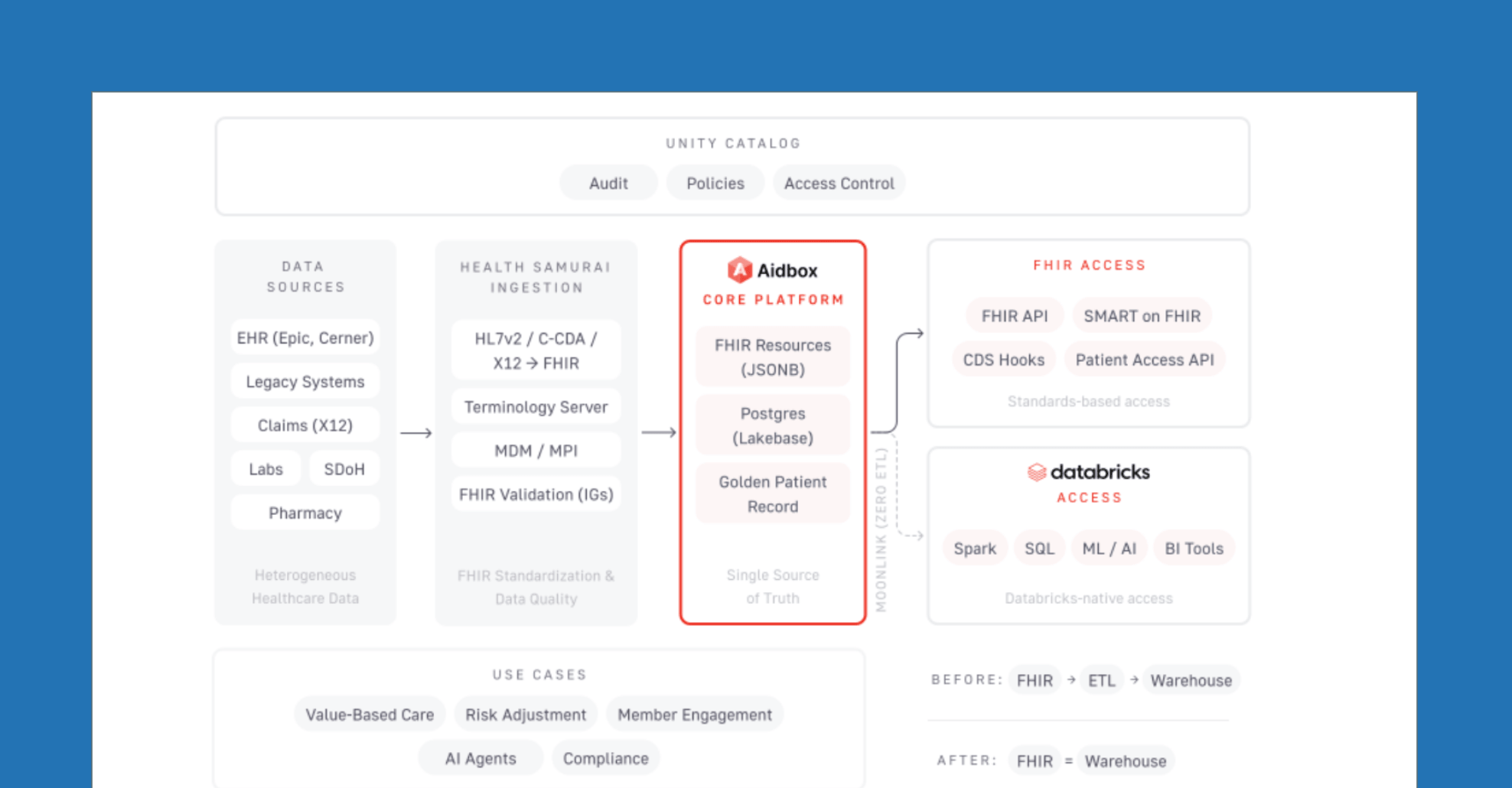
Healthcare data lives in dozens of systems, EHRs, claims, labs, pharmacy, SDoH, each with its own formats, codes, and duplicates. Turning this fragmented landscape into a unified, FHIR-standardized, and trusted data foundation is a key step towards better outcomes, smarter operations, and regulatory readiness. In this blog, you’ll learn how Health Samurai & Databricks give you the technologies to build that foundation on open standards, at any scale.
Today, intelligent healthcare applications don't live at the edge of the business. They run the business; from closing care gaps proactively to powering real-time member engagement to ensuring regulatory compliance by design. But these applications demand a data foundation that most healthcare organizations have struggled to build: one that is standardized, governed, and accessible to every tool in the stack without moving data between systems.
What if your operational intelligence and your analytics capabilities were unified and truly interoperable, driving the same insights?
Healthcare's data landscape is uniquely complex. Patient information is spread across HL7v2 messages, C-CDA documents, X12 transactions, and proprietary formats, each system encoding the same clinical concepts differently. A single diagnosis may appear under multiple codes across multiple vocabularies. A single patient may exist as several records across several systems.
The traditional approach to unifying this data involves standing up a FHIR server for interoperability, a separate data warehouse for analytics, and a web of ETL pipelines connecting the two. Each system maintains its own access controls, audit trails, and compliance posture.
This duplication is costly. The same clinical data is replicated across the FHIR server, the warehouse, and multiple staging layers — each adding storage, compute, and operational overhead. Meanwhile, the FHIR server itself often becomes a bottleneck. Most implementations were designed for transactional use cases — document exchange, point lookups, regulatory APIs — not for the access patterns of modern analytics, ML pipelines, or AI agents that need to scan millions of resources efficiently.