Original article excerpt
Server-side extracted preview paragraphs from the original source.
A Blog post by NVIDIA on Hugging Face
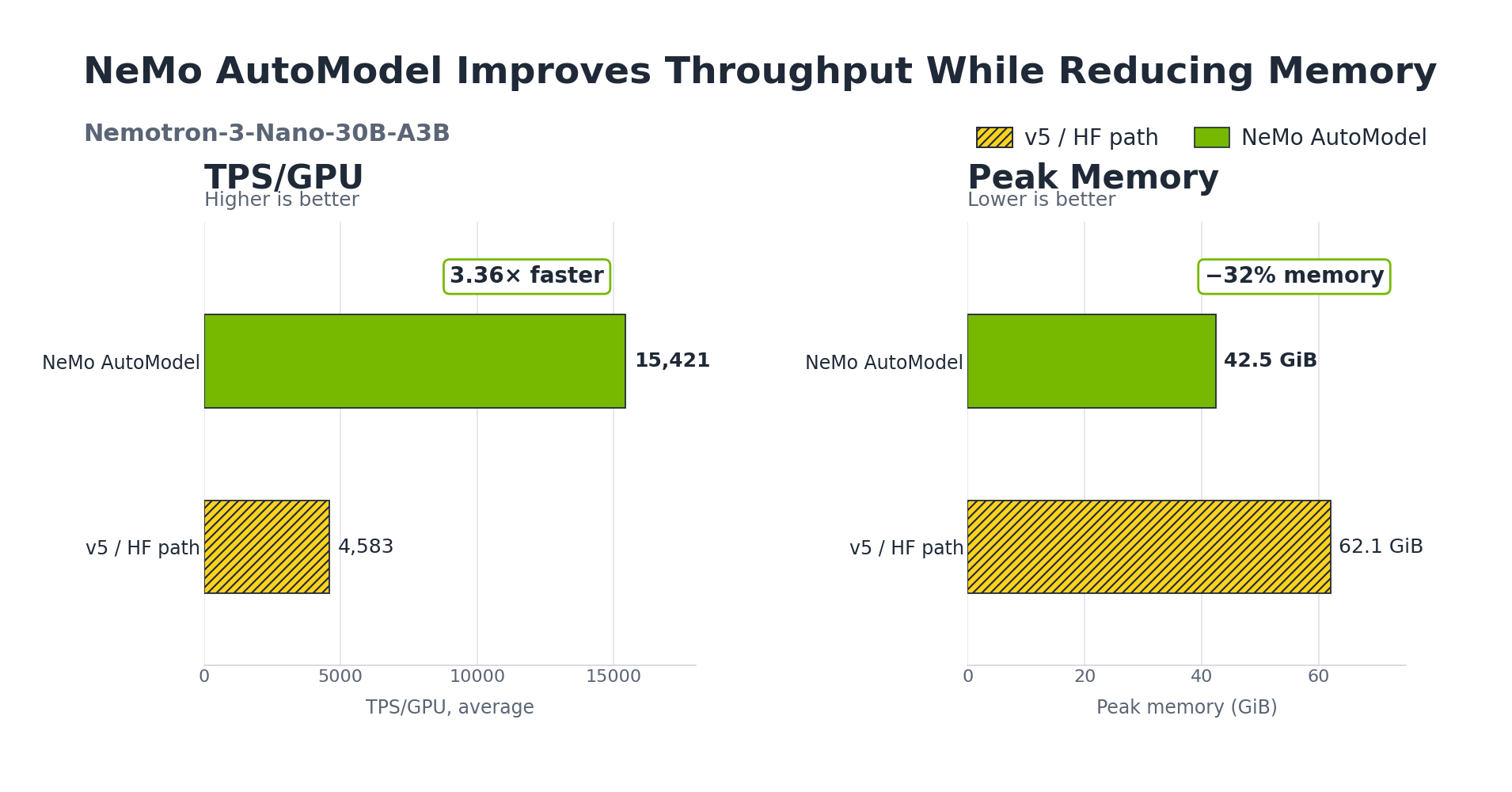
NVIDIA NeMo AutoModel is an open library part of the NVIDIA NeMo framework for building custom generative AI models at scale. NeMo AutoModel builds cleanly on top of v5, adding Expert Parallelism, DeepEP fused all-to-all dispatch, and TransformerEngine kernels, and it leans on v5's dynamic weight loading to bring those optimizations to a broad and growing set of model families. The payoff is 3.4-3.7x higher training throughput and 29-32% less GPU memory on fine-tuning MoE models than native Transformers v5, using the same from_pretrained() API: a single import line, with no other code changes.
This blog details how this combination works and how users can fine-tune MoE models faster without changing their APIs.
The rise of MoE models has introduced new challenges to efficient training: Routing tokens across hundreds of experts, fusing expert matmuls into a single kernel, sharding weights across GPUs, and overlapping communication with computation all require infrastructure beyond what a general-purpose library provides out of the box.
Transformers v5 (“v5”) introduced first-class MoE support such as expert backends, dynamic weight loading, and tensor parallel plans for distributed execution. In addition, v5 made distributed training first-class by integrating PyTorch's DeviceMesh directly into from_pretrained().
NeMo AutoModel builds on top of v5 by subclassing AutoModelForCausalLM, and adding Expert Parallelism (EP), DeepEP fused all-to-all dispatch, and TransformerEngine kernels. DeepEP is the piece v5 doesn't have yet: it overlaps communication with expert compute. And because NeMo AutoModel rides v5's reversible weight conversion to load each model, it can focus its engineering on these reusable core ops instead of per-model checkpoint plumbing, while save_pretrained() still emits standard HF checkpoints that tools like vLLM and SGLang can load.
The next section walks through how the two work together and the performance gains we measured, from full fine-tuning NVIDIA Nemotron 3 Ultra 550B A55B across 16 nodes down to single-node models such as Qwen3-30B-A3B and Nemotron 3 Nano 30B A3B.